
The agent economy has a verification problem


When you call a model API, you trust the provider to run the model you asked for. Not a quantized variant. Not a cheaper substitute routed in when load spikes. You can check tokens. You can diff outputs. What you cannot do is verify that the bytes flowing through the GPU were the bytes of the model you were promised.
A March 2026 paper from Offchain Labs, Towards Verifiable AI with Lightweight Cryptographic Proofs of Inference, gives a concrete answer for the inference piece of that question, collapsing proof generation from roughly 15 minutes per query down to milliseconds. The direction of the answer should feel familiar to anyone who has thought about how Arbitrum works.
The trust gap we've already accepted
Per-token pricing creates an economic incentive to cheat. Serving a 7B parameter model is cheaper than serving a 70B one. Quantized inference is cheaper than full precision. If a provider can route some fraction of requests to a smaller or cheaper model and bill at the headline rate, the savings compound at scale.
This is not hypothetical. Stanford researchers showed that the behavior of GPT-3.5 and GPT-4 shifted measurably between March and June 2023 on the same evaluation tasks, and a follow-on line of work has formalized the problem of detecting outright model substitution in LLM APIs. None of this is an accusation against any specific provider. The point is that today's API contract gives you no mechanism to know either way. For an individual developer that is a nuisance. For regulated industries, model governance teams, and the emerging agent-to-agent settlement layer, it is a load-bearing gap.
Why the cryptographic answer does not work yet
There is already a class of cryptographic proofs that can show a server ran a specific computation correctly without the client having to re-run it. The same family of tools used by zk-rollups. Attach a proof to the response, the client verifies it in a fraction of the original work. So the obvious move is to do the same thing for AI inference.
The math works. The numbers do not.
State-of-the-art schemes like zkLLM produce a proof of inference for a 13B parameter LLM in around 15 minutes. For a smaller model like Llama-2-7B, the published numbers are 388 seconds of proving time per query, with a 183 kB proof and a 2.36 second verification.
That is fine for a research demo. It is not fine for an API expected to respond in under a second. Inference is fast and customers expect it to stay fast, so the proof has to be comparably fast or it becomes the bottleneck.
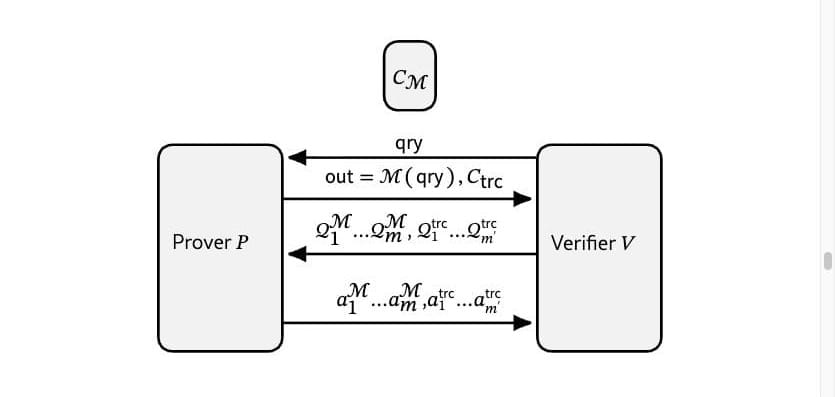
The bet: spot-check instead of re-prove
The Offchain Labs paper takes a different route. Instead of cryptographically proving every multiply-and-add inside the neural network, the server commits to two things up front:
1. A fingerprint of the model weights, published once after training.
2. A fingerprint of the internal values the model produced while answering a specific query.
Then the client picks a random spot near the network's output and walks one path back through the layers, asking the server to reveal just the values along that path. At each step, the client checks one thing. Does this value actually follow from the values feeding into it, using the weights it committed to publicly? If the server swapped in a different model, the values along the path will not line up, and the check fails.

It is closer to spot-checking a math exam than re-grading it. A single path samples a tiny fraction of the network, but faking values that stay self-consistent across many possible paths gets exponentially harder as the network grows. The authors tested this against the attacks an adversary would actually try, including reverse-engineering the activations from the output and swapping likely tokens. None produced a forged set of values that fooled the test across millions of evaluated paths.
The intuition behind why this works comes from machine learning research, not cryptography. Two networks that produce noticeably different outputs on the same input have to differ in their internal computation somewhere. You do not need to re-execute the whole model to catch a cheater. You need to catch them in one consistent lie.
From minutes to milliseconds
The performance difference between proving every step and spot-checking a path is not a few percent. It is several orders of magnitude.

Both numbers are on the same model, Llama-2-7B. The tradeoff is honest. The proof is larger, and the client no longer gets cryptographic certainty per query. What it gets is a tunable detection probability that compounds across repeated queries, which combined with a real penalty for being caught is enough to deter rational adversaries.
An API serving millions of inferences a day does not need a per-query proof that holds up against an attacker willing to brute force a single transcript. It needs verification that runs at the speed of the request and detects cheating with high probability across volume. That is the shape the new protocol fits.
Why this story belongs on Arbitrum
Sub-second verification of an outsourced computation is the question Arbitrum was initially built around.
Optimistic rollups rest on the same intuition the paper formalizes for AI. Re-executing every step of a long computation on every machine is expensive. Sampling the contested step is cheap. If the system can guarantee that any disagreement gets surfaced and resolved by a tiny onchain check, you get the security of full re-execution without paying for it on the happy path.
The paper makes the connection explicit. Its protocol can extend to a setup with two competing servers, and when they produce different claims about the same inference, a bisection procedure narrows in on the disagreement in a logarithmic number of rounds. That is the same dispute resolution structure that secures Arbitrum One, applied to neural network values instead of blockchain state transitions.
The takeaway is not that AI inference needs a blockchain. It is that the verification problem in the agent economy has the same shape as the verification problem Arbitrum already solved. Spot-check rather than re-execute. Trust the willingness to be challenged rather than the cryptographic load on the happy path. Arbitrum has been operating in that paradigm for years.
What this means if you build with AI APIs
Settlement is converging on commodity rails. USDC, x402, agent-native payment flows are infrastructure questions now, not differentiation questions, and the more interesting layer is what the agent can prove it did, not how it paid.
Today, "we use model X" is a trust statement. A protocol like this one turns it into a verifiable statement. For customers in compliance-heavy domains, the distinction starts to matter quickly. A model transparency claim that holds up under audit is worth more than a marketing claim that does not.
The pattern also generalizes. Anywhere you outsource a deterministic computation to an untrusted service, spot-checking is a viable alternative to re-executing. Inference today, other workloads tomorrow. Audit flows benefit too, since a regulator who needs to verify that a certified model is the one actually running in production does not have to ban remote APIs to do the job. They can ask for a commitment, send queries, and check.
None of this requires that you, the application developer, refactor your existing stack. It does require that someone in the system, the provider, the auditor, or the platform routing requests, produces a verifiable claim instead of an asserted one. Once that primitive exists at speed, it gets adopted in the places where the trust gap is most expensive.
Where this is going
The agent economy has mostly been told as a money-movement story, and moving money is perhaps the part with the most familiar primitives. The verification layer is less well-formed, and that is exactly why this research is so interesting right now.
The Offchain paper does not solve the integrity problem entirely. It offers a way forward for the inference piece against a meaningful threat model, in milliseconds. That is worth paying attention to, and a useful indicator of where the future of verifiable AI inference is going.

The signature builder program, Open House, is coming to London in July for an in-person Founder House, with agentic AI as one of the focus areas. Do you have an idea related to how to tackle trust in AI or any topic related to this emerging space? If you want to bring your idea to life with the support of leading ecosystem mentors and the chance to win grants and prizes totaling in the hundreds of thousands of dollars, apply to join today.